Gamer
Administrator
 Din: Transilvania
Inregistrat: acum 14 ani
Postari: 202
|
|
Cuvânt înainte
Având o istorie de peste 30 de ani, sistemul de operare UNIX s-a impus pe piaţa sistemelor de operare de reţea ca un sistem robust, fiabil, portabil, capabil să ruleze pe cele mai variate arhitecturi hardware.
Conform opiniilor specialiştilor în domeniu, UNIX reprezintă sistemul de operare original. De fapt, Microsoft Windows şi MacOS (sistemul de operare ce rulează pe Macintosh) au fost iniţial dezvoltate ca alternative la UNIX şi nu invers.
Cu toate că majoritatea PC-urilor actuale utilizează Windows, în ultimul timp se observă o tendinţă din ce în ce mai puternică spre utilizarea Linux-ului (care nu este altceva decât o variantă de UNIX) care are un mare avantaj: este gratis! De asemenea, ultimele tipuri de interfeţe grafice precum CDE (Common Desktop Environment), GNOME, KDE facilitează folosirea UNIX-ului pentru utilizatorii care nu sunt specialişti în domeniul calculatoarelor.
Pe de altă parte, cunoştinţele legate de UNIX pot reprezenta o avere deosebită în lumea de astăzi a tehnologiei informaţiei. Multe dintre cele mai puternice reţele din lume şi site-uri Internet sunt bazate pe UNIX, existând o cerere deosebită pentru profesionişti specializaţi în administrarea sistemelor UNIX. Aceşti administratori de sisteme (cunoscuţi şi sub denumirea de sysadmin) sunt printre cei mai bine plătiţi oameni din domeniul IT.
În primul capitol al lucrării de faţă sunt prezentate caracteristicile generale ale sistemului de operare UNIX, istoric, tipuri de implementări, documentare, comenzi şi interfeţe grafice.
În capitolul al doilea sunt prezentate noţiuni legate de sistemul de fişiere UNIX precum şi comenzi referitoare la fişiere şi directoare.
Capitolul al treilea se referă la administrarea fişierelor, comenzi legate de partiţii şi hard-disc-uri, căutarea şi sortarea fişierelor, arhivarea şi compresia fişierelor.
În capitolul al patrulea sunt prezentate serviciile de reţea oferite în UNIX, serviciile ARPA precum şi posibilitatea integrării cu alte sisteme de operare.
Capitolul al cincilea face referire la editoare de texte utilizate pe sisteme UNIX; sunt prezentate aici editorul vi şi editorul pico.
În capitolul al şaselea sunt prezentate noţiuni generale legate de shell-uri UNIX, variante, procese UNIX şi mediul de lucru.
1.1 Introducere
Sistemul de operare UNIX, împreună cu suita de protocoale TCP/IP pentru comunicaţia în reţea şi cu sistemul de fişiere NFS constituie o soluţie convenabilă pentru constituirea unui sistem complet de operare în reţea.
Dezvoltat iniţial în laboratoarele AT&T Bell Labs (cu participarea companiei General Electric şi a faimosului MIT Massachusetts Institute of Technology), UNIX-ul reprezintă, de fapt, o mare familie de sisteme de operare înrudite ce descind din munca programatorilor Dennis Ritchie şi Ken Thompson (creatorii limbajului C) la sfârşitul anilor 60 şi începutul anilor 70. Sistemele din familia UNIX pot fi rulate pe orice tip de calculator, plecând de la calculatoarele personale până la super-calculatoarele cu configuraţii extrem de avansate, utilizate îndeosebi în domeniul militar şi cel bancar. De asemenea, toate variantele de UNIX sunt multitasking, domeniu în care UNIX are o reputaţie deosebită.
Numele său derivă de la un jos de cuvinte al unui alt proiect Bell Labs/MIT din acelaşi timp produs pe un calculator mainframe cunoscut sub numele de Multics (Multiplexed Information and Computing Service).
Sistemul de operare interactiv Multics fusese scris pentru un computer al companiei General Electric dovedindu-se după ani de dezvoltare mult prea costisitor, de aceea Bell Labs s-a retras ulterior din proiect.
În timpul lucrului la proiectul Multics, programatorul Ken Thompson a scris un joc de călătorie în spaţiu pentru computerul
General Electric. După sistarea proiectului, acesta a rescris jocul împreună cu colegul său Dennis Ritchie pentru a rula pe un computer DEC PDP-7 ce avea un display grafic mai performant. Acest calculator avea nevoie însă de un sistem de operare viabil. Iniţial, noul sistem de operare a fost numit de către Thompson UNICS (Uniplexed Information and Computing Service), apoi numele său s-a schimbat în UNIX iar jocul de călătorie spaţială a fost modificat pentru a rula sub UNIX.
Cu toate îmbunătăţirile aduse de-a lungul timpurilor, de la primele implementări de UNIX şi până acum, toate variaţiile sale urmăresc într-o mare măsură arhitectura şi funcţionalitatea originală UNIX.
Prin multitasking se înţelege capacitatea unui sistem de operare de a executa mai multe procese (task-uri) simultan. Acest lucru se realizează prin fenomenul time slicing ce presupune că fiecare proces aflat în execuţie utilizează calculatorul pentru o perioadădeterminată de timp. Comportamentul multitasking este în opoziţie cu task switching, caz în care fiecare proces aflat în execuţie trebuie să se termine pentru a se începe execuţia unui nou proces.
1.2 Scurt istoric
Pentru a înţelege mai bine caracteristicile acestui sistem de operare, avantajele şi dezavantajele sale, este util să cunoaştem câteva lucruri legate de istoria sa.
După cum am spus mai înainte, UNIX a fost conceput iniţial la Bell Laboratories USA drept un proiect privat de cercetare, proiect început în 1969 de către un mic colectiv de cercetători. Scopul acestui colectiv de cercetare era acela de a concepe un sistem de operare care să corespundă următoarelor exigenţe: să fie elegant, simplu şi concis; să fie scris într-un limbaj de programare de nivel înalt şi nu în limbaj de asamblare; să permită refolosirea codului.
La început, UNIX a fost scris în limbaj de asamblare şi de aceea nu putea rula decât pe un calculator anume. Odată cu naşterea limbajului C în 1971, Ritchie şi Thompson au rescris în 1973 programele de sistem UNIX în C. În acest fel UNIX-ul putea fi mutat (portat) şi pe alte calculatoare fără un efort prea mare de programare. În aceeaşi perioadă, compania AT&T (firmă mamă pentru Bell Laboratories) a fost declarată monopol de Comisia
Federală de Comerţ a SUA. Drept compensaţie, Bell Laboratories a oferit gratis sistemul de operare UNIX universităţilor din SUA, astfel încât acesta a devenit extrem de popular în mediul academic. Cu timpul, UNIX s-a răspândit şi în mediul comercial, în care studenţii aplicau ceea ce au învăţat pe băncile universităţilor.
Spre deosebire de majoritatea producătorilor de sisteme de operare din acel timp, care produceau sisteme mari şi scrise în limbaj de asamblare, UNIX avea un mic procent de cod scris în limbaj de asamblare (aproximativ 10% - kernelul), în timp ce restul codului era scris în C. Grupul de dezvoltare a sistemului a conceput iniţial munca în limbaj de nivel înalt, apoi, odată cu dezvoltarea sa, au apărut mici schimbări ce au fost făcute în kernel şi în limbajul de programare pentru a se definitiva UNIX-ul.
În cadrul acestei evoluţii continue, kernelul şi software-ul aferent au fost extinse până când s-a creat un sistem de operare scris în C, bazat pe kernelul în limbaj de asamblare. Codul sursă al sistemului de operare UNIX a fost făcut public şi disponibil universităţilor de pe întreg teritoriul SUA. Programatorii de la Universitatea Berkeley din California au făcut modificări substanţiale codului sursă original şi astfel s-a născut BSD (Berkeley Software Distribution) UNIX. Această nouă versiune de UNIX a fost făcută cunoscută la rândul ei programatorilor din SUA care au adăugat instrumente şi cod. Cea mai importantă îmbunătăţire adusă sistemului de operare de către programatorii de la Berkeley a fost adăugarea software-ului de reţea ce permis sistemului de operare să funcţioneze într-o reţea locală. Varianta BSD UNIX a devenit extrem de populară printre producătorii de computere, dintre care: Hewlett Packard, Digital Equipment Corporation şi Sun Microsystems.
Scurt istoric al sistemului de operare UNIX
Tabelul 1.1
Code:
1969 Începutul dezvoltării a ceea ce urma să devină UNIX de către programatorii Ken Thompson
şi Dennis Ritchie la Bell Laboratories.
1973 UNIX este rescris în C pentru a fi portabil şi a putea rula pe diverse computere.
1975 Se distribuie versiunea 6 în afara laboratoarelor Bell; prima versiune BSD derivă din această versiune V6.
1980 Microsoft produce Xenix iar BSD 4.2 este larg utilizat.
1984 Universitatea Berkeley din California distribuie versiunea 4.2 BSD ce include suita de protocoale TCP/IP
pentru reţea şi alte programe aplicative.
1984 Apare versiunea SVR2 (System V Release 2); există aproximativ 100.000 de instalări de UNIX în întreaga lume.
1986 Apare versiunea 4.3BSD ce include internet name server.
1987 Apare versiunea SVR3; în acest moment există aproximativ 750.000 de instalări de UNIX în întreaga lume.
1988 Apare UNIX SVR4 prin unificarea versiunilor System V, BSD şi Xenix.
1991 UNIX System Laboratories (USL) devine o companie în care acţionar majoritar este
AT&T; Linus Torvalds începe dezvoltarea Linux-ului.
1992 USL elaborează UNIX SVR4.2 iar Novell îşi anunţă intenţia de a prelua USL.
1993 Apare versiunea 4.4BSD de la Berkeley. Novell preia USL.
1999 UNIX împlineşte 30 de ani; kernel-ul Linux ajunge la versiunea 2.2.
2001 Versiunea 3 Single UNIX Specifications reuneşte eforturile POSIX, The Open Group şi ale altor companii.
Kernel-ul Linux ajunge la varianta 2.4
2003 Kernel-ul Linux ajunge la versiunea 2.5
2004 Se află în lucru variante ale kernel-ului Linux versiunea 2.6 |
În timp ce firma Sun Microsystems avea sistemul de operare SunOS bazat pe versiunea BSD UNIX 4.2, compania AT&T folosea o versiune de UNIX cunoscută sub numele de System V (system five). În anul 1988, SunOS/BSD, AT&T System V Release 3 şi XENIX (o versiune de UNIX dezvoltată de Microsoft pentru PC-uri cu procesoare Intel) au fost combinate într-o nouă versiune UNIX denumită System V Release 4 (SVR4). Această nouă generaţie a sistemului de operare UNIX a fost creată în scopul combinării celor mai bune caracteristici din varianta BSD cât şi din varianta AT&T System V pentru a crea un standard în industria sistemelor de operare. Acest lucru a permis dezvoltarea de software pentru UNIX indiferent că era vorba despre System V sau BSD 4.2. Noua variantă SVR4 a devenit baza celor mai multe varietăţi de UNIX.
În tabelul 1.1 regăsim istoria de peste 30 de ani a sistemului de operare UNIX.
1.3 UNIX sistem de operare pentru reţea
Ca un vechi şi adevărat sistem de operare pentru reţea, UNIX oferă facilităţi avansate în acest sens, printre care:
Operare multi-utilizator
* Multitasking
* Procesare distribuită
* Nivel ridicat de securitate
Facilitatea de operare multi-utilizator permite accesul simultan la sistem pentru mai mulţi utilizatori ce pot astfel partaja aceleaşi resurse ale sistemului. Sistemul de operare are grijă de fiecare resursă a computerului, fie că este vorba de memoria RAM, microprocesor, hard disk, scanner sau imprimantă, permiţând partajarea fiecăreia dintre acestea. Fiecare program aflat în execuţie poartă numele de proces sau task. Sistemul de operare UNIX ţine evidenţa mai multor procese simultan această capacitate a sa este denumită multitasking. Acest fapt permite mai multor aplicaţii să ruleze în acelaşi timp pe computer. De asemenea, capacitatea de procesare distribuită a sistemului de operare se referă la faptul că acesta permite utilizarea partajată a resurselor în cadrul reţelei. Cel mai simplu exemplu în acest sens este acela în care un utilizator poate accesa fişiere şi aplicaţii de pe hard disk-ul altui computer situat în altă parte a reţelei de calculatoare.
În fine, sistemele de operare pentru reţea au implementate sisteme de securitate foarte sigure; există multe alte facilităţi de asigurare a securităţii în afară de cea clasică nume-de utilizator/parolă. De regulă, facilităţile de asigurare a securităţii sistemului pot fi active sau nu, în funcţie de politicile de securitate implementate la nivelul companiei respective.
1.4 Arhitectura UNIX
Sistemul de operare UNIX este un sistem de operare structurat în principal pe următoarele două nivele:
* Programe sistem UNIX;
* Nucleul (denumit kernel) sistemului UNIX.
Majoritatea programelor sistem şi kernel sunt scrise în C, permiţând portabilitatea pe alte platforme hardware ce posedă un compilator C.
Programele de sistem UNIX oferă funcţionalitatea cerută de utilizatori prin iniţierea unui sistem de apeluri către nucleul sistemului UNIX. Nucleul îndeplineşte aceste cereri interacţionând cu nivelul hardware şi returnând rezultatele scontate utilitarelor şi programelor sistem. În această arhitectură stratificată, doar nucleul UNIX trebuie să se ocupe de echipamentele hardware specifice cu care trebuie să interacţioneze; în interiorul nucleului majoritatea codului specific hardware se limitează la driverele echipamentelor.
Nucleul reprezintă centrul sistemului de operare şi are rolul de a oferi funcţionalităţile de bază necesare funcţionării computerului. Nucleul este apropiat de microprocesor şi hardware, fiind un fişier executabil ce este încărcat în memorie atunci când are loc procesul de boot al calculatorului, fiind denumit generic unix (pe sistemele bazate pe System V) sau vmunix(pe sistemele bazate pe BSD). Odată cu încărcarea în memorie, nucleul începe execuţia următoarelor funcţii:
* Administrarea echipamentelor, a memoriei şi a proceselor;
* Asigură controlul funcţiilor de transmisie a informaţiilor între programele de sistem şi echipamentele hardware;
* Administrează entităţi precum spaţiul de swap, demonii şi sistemul de fişiere.
Spaţiul de swap reprezintă o porţiune specială de pe hard-disc ce este folosit de către kernel pentru procesare.
Bucăţi ale programelor ce se află în execuţie pot fi interschimbate între memoria RAM şi hard-disc ori de câte ori este nevoie. Acest mecanism de extindere a memoriei
RAM a sistemului prin utilizarea spaţiului de pe hard-disc poartă denumirea de memorie virtuală.
Demonii sunt programe (sau procese) ce îndeplinesc un anumit rol; ei sunt procese speciale care îşi încep execuţia dupăîncărcarea sistemului de operare în memorie. După aceea, demonii aşteaptă să ruleze anumite sarcini în sprijinul sistemului de operare, putând fi porniţi manual sau în mod automat. Un exemplu de proces demon este dtlogin care determină apariţia ecranului de login CDE la începutul unei sesiuni UNIX sau după ce utilizatorul iese din File Manager-ul CDE. Procesele demon din lumea UNIX sunt similare cu serviciile (services) din Windows NT/2000/XP sau cu modulele NLM (Netware Loadable Modules) din sistemul de operare Novell Netware.
Sistemele de fişiere reprezintă modalitatea de organizare a directoarelor, subdirectoarelor, fişierelor pe hard-disc.
Sistemele de fişiere pot fi situate atât local (pe calculatorul local) cât şi la distanţă (pe alt calculator din reţea, de regulă un aşa numit server).
Programele şi utilitarele sistemului, precum şi aplicaţiile utilizatorilor sunt independente de hardware şi singura cerinţă pentru acestea este să iniţieze apeluri standardizate de sistem către nucleul UNIX. Cele mai multe dintre funcţiile nucleului UNIX se ocupă de managementul fişierelor sau al anumitor tipuri de dispozitive. Pentru a simplifica şi standardiza apelurile de sistem, UNIX interpretează echipamentele ca fiind tipuri speciale de fişiere. Poate cea mai importantă caracteristică a sistemului UNIX este aceea a disponibilităţii codului sursă, ceea ce permite multor programatori să îmbunătăţească şi să modifice aceste sistem de operare de-a lungul anilor. Cele două proprietăţi remarcabile ale sistemului de operare UNIX sunt:
* Portabilitatea aceasta se manifestă în două moduri: în primul rând, UNIX este portabil pe numeroase platforme hardware; în al doilea rând, programele scrise pentru UNIX sunt implicit portabile pe toate platformele UNIX, depinzând de nivelul de similaritate între nucleele şi programele de sistem UNIX;
* Modularitatea UNIX este un sistem dinamic, a cărui funcţionalitate poate fi îmbunătăţită prin adăugarea de noi programe utilitare; de asemenea, este posibilă şi modificarea nucleului şi recompilarea sa pentru un sistem de operare mai bun.
Arhitectura generală şi cele mai importante funcţii ale nucleului UNIX sunt prezentate în figura 1.2.
1.5 Funcţionalităţi UNIX
Dintre cele mai importante caracteristici funcţionale ale sistemului de operare UNIX se disting următoarele:
* Operare multiutilizator;
* Multitasking preemtiv;
* Multiprocesare;
* Suport pentru aplicaţii multi-threaded.
O altă caracteristică importantă este aceea a managementului memoriei care este realizat prin două metode de bază: memoria virtuală (prin procedeul de swapping) şi paginarea. Prima metodă permite interschimbarea proceselor între memoria fizică şi partiţia de swap de pe hard disc, în timp ce procedeul de paginare caută să elimine sau cel puţin să minimizeze fragmentarea (care apare în procesul de swapping), permiţând astfel proceselor să execute doar acele porţiuni ale acestora care sunt prezente în memoria principală. Aceste porţiuni de dimensiune fixă încărcate în memoria principală la cerere sunt cunoscute sub denumirea de pagini, iar întregul proces este referit sub numele de sistemul de memorie virtuală (bazat pe cereri de pagini).
Altă funcţionalitate de bază este aceea oferită de sistemul de intrare/ieşire care încearcă să minimizeze interacţiunile (specifice hardware) necesitate de nucleul UNIX. Sistemul de intrare/ieşire al sistemului de operare UNIX este alcătuit din:
* Interfaţa socket, folosită pentru comunicaţiile între procese;
* Driverul dispozitivelor bloc, folosit pentru comunicarea cu dispozitive orientate pe bloc (de exemplu hard discuri sau unităţi de bandă . Transferurile efectuate de astfel de dispozitive se fac de regulă în blocuri de lungime fixă de 512 sau 1024 octeţi; . Transferurile efectuate de astfel de dispozitive se fac de regulă în blocuri de lungime fixă de 512 sau 1024 octeţi;
* Driverul dispozitivelor orientate caracter, folosite pentru comunicarea cu dispozitivelor orientate pe caracter (terminale, imprimante sau alte dispozitive care nu transferă date în blocuri de octeţi de dimensiune fixă.
În fine, un rol de bază în funcţionarea sistemului UNIX îl are controlul proceselor şi intercomunicarea între procese (asigurată prin mecanismul de conductă pipe- fie prin sockets).
1.6 Implementări de UNIX
Două dintre familiile importante ale sistemului de operare UNIX sunt:
* UNIX System V Release 4, cunoscut de regulă sub denumirea de SVR4 sau V.4, derivă din modelul original dezvoltat la Bell Laboratories, cunoscut mai târziu sub numele de UNIX Systems Laboratory (USL) şi vândut apoi către SCO (Santa Cruz Operation) şi Berkeley Software Distribution (BSD) versiunea 4.4., variantă cunoscută sub denumirea de 4.4BSD.
Există însă o mare varietate de sisteme de operare UNIX, majoritatea acestora fiind similare deoarece sunt bazate pe standardul SVR4. Celelalte varietăţi sunt bazate pe BSD. Cele mai multe diferenţe apar la comenzile de administrare a sistemului. Putem spune dacă lucrăm pe un sistem de operare bazat pe System V sau BSD şi după comenzile de printare (lp pentru System V şi lpr pentru BSD) şi de vizualizare a proceselor lansate în execuţie (ps ef pentru System V şi ps aux pentru BSD)
UNIX a devenit o marcă înregistrată (deţinută de The Open Group ), de aceea fiecare producător de UNIX şi-a ales propriul nume. Spre exemplu, versiunea de UNIX a firmei Sun se numeşte Solaris, a firmei IBM se numeşte AIX iar a firmei Hewlett Packard se intitulează HP-UX. În tabelul 1.3 sunt prezentate o serie de implementări UNIX, platformele hardware pe care acestea activează precum şi vânzătorii produselor.
Aceste variante de UNIX sunt concepute să ruleze pe platformele hardware specifice firmelor care le-au dezvoltat. Unele variante însă rulează pe mai multe platforme hardware; spre exemplu, Solaris rulează atât pe staţii de lucru Sun cât şi pe staţii cu microprocesoare Intel şi până la computere de tip mainframe şi supercomputere.
Ultimul sistem de operare derivat din kernelul UNIX îl reprezintăLinux-ul, conceput să ruleze pe microprocesorul Intel de la staţii de lucru ieftine (chiar şi 386!) până la servere performante. Linux-ul a devenit foarte popular printre specialiştii entuziaşti ai computerelor în necesitatea găsirii unui sistem de operare stabil şi ieftin.
Totul a plecat în 1992 de la Linus Torvalds de la Universitatea din Helsinki, Finlanda, care a făcut public Linux-ul pe Internet şi a încurajat pe toată lumea să contribuie la dezvoltarea sa. În mod periodic un grup de dezvoltatori revizuiesc şi testează ultimile contribuţii şi elaborează o versiune stabilă a sistemulului de operare. Linux este gratis conform GNU General Public Licence ) dar există o serie de companii care adaugă sistemului produse de tip Office, interfeţe desktop, software pentru Web server, etc. precum şi CD-uri de instalare şi percep astfel o taxă (care este, oricum, mult mai mică decât a oricărui alt sistem de operare comercial).
1.7 GNU Not UNIX, free software şi open source
Conceptul de free software este un concept vechi; primele calculatoare personale au ajuns prima dată în universităţi, fiind instrumente de cercetare. Software-ul putea fi instalat în mod liber pe orice calculator, iar programatorii (puţini, la acea vreme) erau plătiţi pentru activitatea de programare, nu pentru programele în sine pe care le realizau. Ceva mai târziu însă,atunci când calculatoarele personale au intrat în lumea afacerilor, programatorii au început să restricţioneze drepturile de folosire a softwareului pe care îl produceau, percepând taxe de utilizare pentru copiile programelor.
Numele de GNU provine de la sintagma GNU Not UNIX şi s-a dorit a fi un sistem de operare precum UNIX ce este distribuit cu codul sursă şi poate fi copiat, modificat şi redistribuit. Proiectul GNU a fost iniţiat în 1983 de Richard Stallman şi alţii ce au pus bazele Fundaţiei pentru Software Liber (FSF Free Software Foundation). Concepţia lui Stallman este aceea că utilizatorii pot face ce doresc cu software-ul achiziţionat, putând face cópii ale acestuia pentru prieteni şi modifica codul sursă redistribuind-ul la un anumit cost. FSF stipulează termenul copyleft care înseamnă că oricine redistribuie software free trebuie să lase în continuare libertatea de copiere şi redistribuţie a programului, asigurându-se în acest fel că nimeni nu va reclama drepturi de proprietate asupra unor versiuni viitoare şi nu va impune restricţii la utilizarea acestuia.
În acest context, termenul free înseamnă libertate şi nu neapărat gratis. Fundaţia FSF percepe nişte costuri iniţiale la distribuţia GNU. Redistribuitorii pot, de asemenea, să perceapă taxe pentru copiile programelor în scopul profitului sau pentru acoperirea costurilor. Ideea de bază a software-ului liber (free software) este aceea că se lasă libertatea utilizatorilor să modifice şi să reasambleze produsul fără nici o restricţie în afară de aceea că nici ei, la rândul lor, nu pot impune restricţii mai departe. Stallman crede că unul dintre rezultatele filozofiei free software este acela că mai multe programe free vor coexista împreună provenind din alte programe free. GNU este un exemplu în acest sens; acesta a devenit un sistem de operare când în august 1996 i-a fost adăugat un kernel (GNU Hurd şi Mach). Fundaţia FSF continuă să dezvolte software free sub formă de programe de aplicaţii; un program de tip spreadsheet este acum disponibil. Sistemul de operare Linux este conceput cu componente GNU iar kernelul este dezvoltat de Linus Torvalds.
Munca lui Stallman a inspirat multe contribuţii de software free, iar definiţia open source conţine multe dintre ideile lui Stallman, putând fi considerată drept un concept derivat. Open Source Definition a luat naştere odată cu distribuţia Debian GNU/Linux. Sistemul de operare Debian, o variantă de Linux populară şi în zilele noastre, a fost construit în întregime pe bază de software free. Cu toate acestea, deoarece avea alte licenţe diferite de copyleft (care era prin definiţie free), Debian a avut ceva probleme în definirea faptului că este free. Cu timpul au fost elaborate o serie de reguli definite în Debian Free Software Guidelines, document ce defineşte
practic software-ul open source.
Partizan împătimit al software-ului free, Eric Raymond a scris un articol intitulat The Cathedral and the Bazaar (Catedrala şi bazarul) în încercarea de a explica ideea de free software. În acest articol, Raymond descrie software-ul comercial ca fiind dezvoltat în stilul unei catedrale, izolat de marea majoritate a dezvoltatorilor independenţi, în timp de software-ul free se construieşte în stil de bazar, oferind un loc de întâlnire pentru oricine doreşte acest lucru. În articol se susţine ideea că modelul de bazar este superior deoarece un număr mult mai mare de utilizatori şi programatori contribuie la dezvoltarea de software mai bun şi într-un timp mai scurt. Toţi cei care doresc să contribuie la scrierea codului pentru proiect sunt bineveniţi, iar cel mai bun cod va fi ales pentru includerea în proiectul final.
GNU s-a vrut iniţial să fie o alternativă la versiunile comerciale de UNIX. Acest lucru nu s-a întâmplat încă, dar Richard Stallman şi alţi programatori muncesc în continuare pentru acest ideal. Paradoxal este că primele succese înregistrate de GNU au fost aplicaţii adiţionale sistemelor proprietare UNIX. Componente GNU precum GNU Emacs, GCC (GNU C Compiler) şi bash (un înlocuitor free pentru Bourne Shell) sunt instalate astăzi implicit pe majoritatea variantelor de UNIX existente.
Articolul The Cathedral and the Bazaar a avut un mare succes şi o mare influenţă ulterior: oficialii de la Netscape au dezvăluit codul sursă al vestitului lor browser web (Netscape Navigator) în speranţa că dezvoltatori independenţi îl vor face mai bun. Mai mult, Netscape a început să îl consulte pe Raymond cu privire la integrarea firmei în curentul free software. La începutul anului 1998, Eric Raymond s-a întâlnit cu o serie de susţinători ai conceptului de free software pentru a discuta modalităţi prin care săîncurajeze şi alte companii precum Netscape să li se alăture. Printre ideile vehiculate atunci, s-a stabilit că termenul free (care în engleză are un sens dual, de liber, dar şi de gratis) sună anti-comercial, drept pentru care au propus termenul de open source drept înlocuitor. Netscape a folosit termenul de open software atunci când a anunţat distribuirea publică a codului sursă pentru Netscape Navigator iar faimoasa editură OReilly and Associates a adoptat acest termen în materialele sale promoţionale. Cu ajutorul acestor două mari firme, termenul de open source a început să aibă mare succes. Similar cu acest concept a luat naştere şi ideea de open hardware cu privire la dispozitivele şi interfeţele hardware. Acest concept însă nu a avut acelaşi succes ca ideea de software open source, dar el încă există şi poate fi studiat la adresa web
1.8 Comenzi şi interfeţe grafice în UNIX
Sistemul de operare UNIX posedă peste 350 de comenzi de sistem şi programe utilitare folosite pentru administrarea sistemului (adăugare de noi utilizatori, noi dispozitive hardware, etc.), administrarea sistemului de fişiere (creare, editare, copiere, ştergere, printare, etc.), asigurarea conexiunii la reţea şi comunicării cu alte sisteme şi oferirea de ajutor.
Interpretorul de comenzi (shell-ul) preia comenzile şi le execută. Unele dintre comenzi sunt înglobate în interpretor, precum comanda cd (change directory) dar marea majoritate a comenzilor se află pe hard-disc, de regulăîn directoare specifice, precum directorul bin (prescurtarea de la binary code).
Toate sistemele de operare moderne au un sistem grafic de interfaţă cu utilizatorul (GUI Graphical User Interface); interfaţa grafică Macintosh, Microsoft Windows sau UNIX CDE sunt exemple de astfel de interfeţe.
Interfaţa grafică CDE (Common Desktop Environment)
Firma Sun Microsystems a fost una dintre primele firme ce a utilizat o interfaţă grafică pentru sistemul de operare UNIX. În anul 1993 s-a format un consorţiu de firme ce comercializau sisteme de operare UNIX, cu scopul de a dezvolta un mediu de interfaţă grafică, integrat, standard şi funcţional.
Printre membrii acestui consorţiu se numărau: Hewlett-Packard, IBM, Novell, Sun Microsystems, companii şi membri ai fundaţiilor OSF (open Software Foundation), X/Open şi XConsortium. CDE este bazat pe standardul Motif, oferind o serie de caracteristici generale, comune cu alte medii desktop, printre care: oferă un mediu GUI de interfaţă între utilizator şi sistemul de operare; include meniuri ce pot fi selectate de către utilizatori şi permite rularea unor programe fără a fi necesară scrierea comenzii la linia de comandă; oferă peste 300 de programe utilitare şi instrumente; permite utilizatorilor să controleze mai multe documente şi aplicaţii pe ecran în acelaşi timp; controlează activităţile din ferestre atât cu ajutorul mouse-ului cât şi cu ajutorul tastaturii.
Ecranul CDE poate fi observat în figura 1.4, cu principalele programe şi instrumente de lucru: calendar, administrare de fişiere, e-mail, administrarea printării etc.
Figura 1.4 Interfaţa grafică CDE
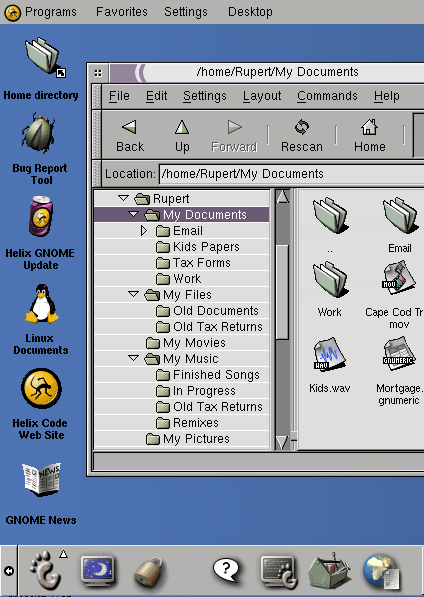
Interfaţa grafică GNOME
O altă interfaţă grafică mai recentă în lumea UNIX este GNU Network Object Model Environment (GNOME) şi face parte din proiectul GNU open source. GNOME (vezi figura 1.5) posedă un mediu grafic uşor de utilizat pentru utilizator precum şi un cadru propice de dezvoltare a aplicaţiilor de asemenea, fiind software open source, este gratis. Interfaţa GNOME ) este inclusă în majoritatea versiunilor de UNIX BSD precum şi în distribuţiile de GNU/Linux. De asemenea, GNOME funcţionează şi cu Sun Solaris ). GNOME posedă o interfaţă intuitivă, uşor de utilizat, combinând o organizare complexă a desktop-ului cu facilităţi de navigare ce permit un acces uşor la informaţii.
Figura 1.5 Interfaţa grafică GNOME
1.9 Documentarea în UNIX
Fie că este vorba despre un începător sau despre un utilizator avansat în utilizarea UNIX-ului, totdeauna este utilă consultarea paginilor de help (care în UNIX se numesc pagini de manual, sau man pages). Dar să vedem cum se poate obţine ajutor în UNIX atunci când vrem să aflăm cum se utilizează o comandă ?
Cea mai la îndemână soluţie este consultarea paginilor de manual, acest lucru făcându-se prin utilizarea comenzii man. A doua soluţie ar fi utilizarea resurselor Internet. În continuare vom prezenta mai pe larg aceste două opţiuni.
1.9.1 Utilizarea comenzii man
Manualul programatorului UNIX (paginile de manual) descriu toate detaliile pe care trebuie să le cunoaştem pentru a utiliza comenzi, a programa sau a administra sistemul. De regulă, paginile de manual sunt instalate automat odată cu instalarea sistemului. Paginile de manual se prezintă sub formă de text, fără grafice, desene, etc. Pentru a accesa paginile de manual trebuie să utilizăm comanda man la prompter. Paginile de manual sunt deosebit de utile fie atunci când am uitat sintaxa unei comenzi sau dorim informaţii în plus cu privire la acea comandă.
Paginile de manual oferă informaţii cu privire la sintaxa generală a comenzii, descrierea funcţionalităţii acesteia, opţiunile şi argumentele utilizate şi exemple de folosire a comenzii. Unele dintre comenzi nu vor funcţiona la fel în cadrul shell-urilor diferite; în acest caz se va face referire la shell-ul Bourne (sh), shell-ul Korn (ksh), shell-ul Bourne Again Shell (bash) sau shell-ul C (csh).
Să vedem în continuare câteva moduri în care poate fi utilizată comanda man:
Oferă informaţii cu privire la o comandă anume, unde nume este denumirea completă a comenzii respective
În figura 1.6 avem ca exemplu o parte din listing-ul obţinut în urma apelului comenzii man ls (informaţii cu privire la comanda ls).
O altă posibilitate de utilizare a comenzii man este aceea în care se foloseşte o anumită secţiune din manualul UNIX, având în vedere că paginile de manual sunt structurate pe mai multe secţiuni.
Dintre aceste secţiuni, cele mai importante sunt: secţiunea 1 - comenzi utilizator, secţiunea 2 - apeluri de sistem, secţiunea 3 - apeluri de biblioteci.
Comenzile precum man(1) sunt grupate deci în secţiunea 1.
Code:
$ man -s nr_sectiune nume |
Oferă informaţii cu privire la o comandă cu numele specificat de nume, în secţiunea nr_sectiune
Observaţie
Această comandă poate să difere de la un sistem la altul. Modalitatea de apel prezentată mai sus se referă la Sun Solaris. Pe un sistem FreeBSD însă, comanda poate fi apelată în felul următor, fără a se specifica opţiunea -s: man nr_sectiune nume.
În cazul în care nu ştim numele comenzii, putem apela comanda man folosind opţiunea -k, prin care facem o căutare după un cuvânt cheie.
Code:
$ man -k cuvant_cheie |
Oferă informaţii cu privire la comenzi referitoare la cuvântul cheie specificat
Exemplul următor ne arată cum am putea căuta informaţii cu privire la modificarea proprietarului (owner) unui fişier:
Code:
$ man -k owner
chown(2), fchown(2), lchown(2) - change owner and group
of a file
chown(8) - change file owner and group
$ |
Listingul anterior conţine o serie de referinţe care conţin cuvântul cheie owner. Pe unele sisteme UNIX acest lucru se poate face utilizând comanda apropos, ca în exemplul următor:
Code:
$ apropos owner
chown(2), fchown(2), lchown(2) - change owner and group
of a file
chown(8) - change file owner and group
$ |
De asemenea, se pot afişa informaţii generale în legătură cu o comandă specificată folosind whatis. Comanda whatis se poate folosi astfel:
Afişează linia de început din cadrul paginii de manual referitoare la comanda specificată
Comanda whatis poate fi utilă în cazul în care ne reamintim comanda dar nu mai ştim la ce se foloseşte.
În mod normal, listingul obţinut în urma unei comenzi man se poate întinde pe multe pagini. În acest sens, este util să cunoaştem câteva taste specifice utilizate pentru navigarea în cadrul paginilor listate pe ecran. În tabelul 1.7 sunt prezentate câteva taste folosite la navigarea prin listingul paginilor de manual.
Taste utilizate pentru deplasarea în cadrul paginilor de manual
1.9.2 Utilizarea referinţelor Internet
Pe Internet există o serie întreagă de documentaţii cu privire la sistemul de operare UNIX. În tabelul 1.8 sunt prezentate câteva adrese web utile ce conţin astfel de documentaţii.
Resurse Internet pentru diverse variante de UNIX
Dintre aceste adrese web, prima ) merită o
atenţie deosebită, deoarece prezintă pagini de manual şi pentru alte versiuni,
cum ar fi:
* BSD, 2.9.1 BSD, 2.10 BSD, 2.11 BSD
* BSD 0.0, 386BSD 0.1
* BSD NET/2, 4.3BSD Reno, 4.4BSD Lite2
* FreeBSD 1.0-RELEASE - FreeBSD 4.0-RELEASE
* FreeBSD 5.0
* FreeBSD Ports
* Linux Slackware 3.1
* Minix 2.0
* NetBSD 1.2 - NetBSD 1.4
* OpenBSD 2.1 - OpenBSD 2.6
* Plan 9
* RedHat Linux/i386 4.2, 5.0, 5.2,etc.
* SunOS 4.1.3, 5.5.1, 5.6, 5.7
* ULTRIX 4.2
* UNIX Seventh Edition
_______________________________________
Citeşte regulamentul forumului aici.
|
|